DAY 7 -AZURE DP900(Explore Azure Storage services--Choose a data storage approach in Azure)
Azure Storage account fundamentals
The Chief Technology Officer (CTO) for your company, Tailwind Traders, has tasked your team with migrating all of your files to the cloud. Your team has chosen Azure Storage, which is a service that you can use to store files, messages, tables, and other types of information. Clients such as websites, mobile apps, desktop applications, and many other types of custom solutions can read data from and write data to Azure Storage. Azure Storage is also used by infrastructure as a service virtual machines, and platform as a service cloud services.
The following video introduces the different services that should be available with Azure Storage.
To begin using Azure Storage, you first create an Azure Storage account to store your data objects. You can create an Azure Storage account by using the Azure portal, PowerShell, or the Azure CLI.
https://www.microsoft.com/en-us/videoplayer/embed/RE4MAbS?postJsllMsg=true

Your storage account will contain all of your Azure Storage data objects, such as blobs, files, and disks.
Note
Azure VMs use Azure Disk Storage to store virtual disks. However, you can't use Azure Disk Storage to store a disk outside of a virtual machine.

A storage account provides a unique namespace for your Azure Storage data, that's accessible from anywhere in the world over HTTP or HTTPS. Data in this account is secure, highly available, durable, and massively scalable.
For more information, see Create a storage account.
Disk storage fundamentals
Disk Storage provides disks for Azure virtual machines. Applications and other services can access and use these disks as needed, similar to how they would in on-premises scenarios. Disk Storage allows data to be persistently stored and accessed from an attached virtual hard disk.
![]()
Disks come in many different sizes and performance levels, from solid-state drives (SSDs) to traditional spinning hard disk drives (HDDs), with varying performance tiers. You can use standard SSD and HDD disks for less critical workloads, premium SSD disks for mission-critical production applications, and ultra disks for data-intensive workloads such as SAP HANA, top tier databases, and transaction-heavy workloads. Azure has consistently delivered enterprise-grade durability for infrastructure as a service (Iaas) disks, with an industry-leading ZERO% annualized failure rate.
The following illustration shows an Azure virtual machine that uses separate disks to store different data.
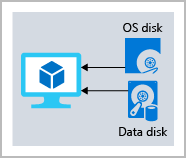
Azure Blob storage fundamentals
Azure Blob Storage is an object storage solution for the cloud. It can store massive amounts of data, such as text or binary data. Azure Blob Storage is unstructured, meaning that there are no restrictions on the kinds of data it can hold. Blob Storage can manage thousands of simultaneous uploads, massive amounts of video data, constantly growing log files, and can be reached from anywhere with an internet connection.
![]()
Blobs aren't limited to common file formats. A blob could contain gigabytes of binary data streamed from a scientific instrument, an encrypted message for another application, or data in a custom format for an app you're developing. One advantage of blob storage over disk storage is that it does not require developers to think about or manage disks; data is uploaded as blobs, and Azure takes care of the physical storage needs.
Blob Storage is ideal for:
- Serving images or documents directly to a browser.
- Storing files for distributed access.
- Streaming video and audio.
- Storing data for backup and restore, disaster recovery, and archiving.
- Storing data for analysis by an on-premises or Azure-hosted service.
- Storing up to 8 TB of data for virtual machines.
You store blobs in containers, which helps you organize your blobs depending on your business needs.
The following diagram illustrates how you might use Azure accounts, containers, and blobs.
Azure Files fundamentals
Azure Files offers fully managed file shares in the cloud that are accessible via the industry standard Server Message Block and Network File System (preview) protocols. Azure file shares can be mounted concurrently by cloud or on-premises deployments of Windows, Linux, and macOS. Applications running in Azure virtual machines or cloud services can mount a file storage share to access file data, just as a desktop application would mount a typical SMB share. Any number of Azure virtual machines or roles can mount and access the file storage share simultaneously. Typical usage scenarios would be to share files anywhere in the world, diagnostic data, or application data sharing.
![]()
Use Azure Files for the following situations:
- Many on-premises applications use file shares. Azure Files makes it easier to migrate those applications that share data to Azure. If you mount the Azure file share to the same drive letter that the on-premises application uses, the part of your application that accesses the file share should work with minimal changes, if any.
- Store configuration files on a file share and access them from multiple VMs. Tools and utilities used by multiple developers in a group can be stored on a file share, ensuring that everybody can find them, and that they use the same version.
- Write data to a file share, and process or analyze the data later. For example, you might want to do this with diagnostic logs, metrics, and crash dumps.
The following illustration shows Azure Files being used to share data between two geographical locations. Azure Files ensures the data is encrypted at rest, and the SMB protocol ensures the data is encrypted in transit.
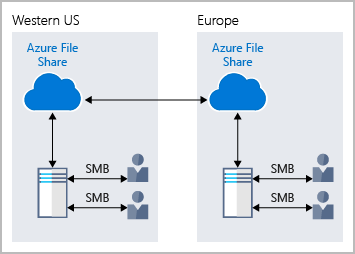
One thing that distinguishes Azure Files from files on a corporate file share is that you can access the files from anywhere in the world, by using a URL that points to the file. You can also use Shared Access Signature (SAS) tokens to allow access to a private asset for a specific amount of time.
Here's an example of a service SAS URI, showing the resource URI and the SAS token:

Understand Blob access tiers
Data stored in the cloud can grow at an exponential pace. To manage costs for your expanding storage needs, it's helpful to organize your data based on attributes like frequency of access and planned retention period. Data stored in the cloud can be different based on how it's generated, processed, and accessed over its lifetime. Some data is actively accessed and modified throughout its lifetime. Some data is accessed frequently early in its lifetime, with access dropping drastically as the data ages. Some data remains idle in the cloud and is rarely, if ever, accessed after it's stored. To accommodate these different access needs, Azure provides several access tiers, which you can use to balance your storage costs with your access needs.
![]()
Azure Storage offers different access tiers for your blob storage, helping you store object data in the most cost-effective manner. The available access tiers include:
- Hot access tier: Optimized for storing data that is accessed frequently (for example, images for your website).
- Cool access tier: Optimized for data that is infrequently accessed and stored for at least 30 days (for example, invoices for your customers).
- Archive access tier: Appropriate for data that is rarely accessed and stored for at least 180 days, with flexible latency requirements (for example, long-term backups).
The following considerations apply to the different access tiers:
- Only the hot and cool access tiers can be set at the account level. The archive access tier isn't available at the account level.
- Hot, cool, and archive tiers can be set at the blob level, during upload or after upload.
- Data in the cool access tier can tolerate slightly lower availability, but still requires high durability, retrieval latency, and throughput characteristics similar to hot data. For cool data, a slightly lower availability service-level agreement (SLA) and higher access costs compared to hot data are acceptable trade-offs for lower storage costs.
- Archive storage stores data offline and offers the lowest storage costs, but also the highest costs to rehydrate and access data.
The following illustration demonstrates choosing between the hot and cool access tiers on a general purpose storage account.

------------------------------------------------------------------------------------------
https://www.microsoft.com/en-us/videoplayer/embed/RE2yEuY?postJsllMsg=true
https://www.microsoft.com/en-us/videoplayer/embed/RE4LBu6?postJsllMsg=true
Classify your data
An online retail business has different types of data. Each type of data may benefit from a different storage solution.
Application data can be classified in one of three ways: structured, semi-structured, and unstructured. Here, you'll learn how to classify your data so that you can choose the appropriate storage solution.
Approaches to storing data in the cloud
Structured data
Structured data, sometimes referred to as relational data, is data that adheres to a strict schema, so all of the data has the same fields or properties. The shared schema allows this type of data to be easily searched with query languages such as SQL (Structured Query Language). This capability makes this data style perfect for applications such as CRM systems, reservations, and inventory management.
Structured data is often stored in database tables with rows and columns with key columns to indicate how one row in a table relates to data in another row of another table. The below image shows data about students and classes with a relationship to grades that ties them together.

Structured data is straightforward in that it's easy to enter, query, and analyze. All of the data follows the same format. However, forcing a consistent structure also means evolution of the data is more difficult as each record has to be updated to conform to the new structure.
Semi-structured data
Semi-structured data is less organized than structured data, and is not stored in a relational format, as the fields do not neatly fit into tables, rows, and columns. Semi-structured data contains tags that make the organization and hierarchy of the data apparent - for example, key/value pairs. Semi-structured data is also referred to as non-relational or NoSQL data. The expression and structure of the data in this style is defined by a serialization language.
For software developers, data serialization languages are important because they can be used to write data stored in memory to a file, sent to another system, parsed and read. The sender and receiver don’t need to know details about the other system, as long as the same serialization language is used, the data can be understood by both systems.
Common formats
Today, there are three common serialization languages you're likely to encounter:
XML, or extensible markup language, was one of the first data languages to receive widespread support. It's text-based, which makes it easily human and machine-readable. In addition, parsers for it can be found for almost all popular development platforms. XML allows you to express relationships and has standards for schema, transformation, and even displaying on the web.
Here's an example of a person with hobbies expressed in XML.
<Person Age="23">
<FirstName>John</FirstName>
<LastName>Smith</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
XML expresses the shape of the data using tags. These tags come in two forms: elements such as <FirstName> and attributes that can be expressed in text like Age="23". Elements can have child elements to express relationships - such as the <Hobbies> tag above which is expressing a collection of Hobby elements.
XML is flexible and can express complex data easily. However, it tends to be more verbose making it larger to store, process, or pass over a network. As a result, other formats have become more popular.
JSON – or JavaScript Object Notation, has a lightweight specification and relies on curly braces to indicate data structure. Compared to XML, it is less verbose and easier to read by humans. JSON is frequently used by web services to return data.
Here's the same person expressed in JSON.
{
"firstName": "John",
"lastName": "Doe",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
Notice that this format isn't as formal as XML. It's closer to a key/value pair model than a formal data expression. As you might guess from the name, JavaScript has built-in support for this format - making it very popular for web development. Like XML, other languages have parsers you can use to work with this data format. The downside to JSON is that it tends to be more programmer-oriented making it harder for non-technical people to read and modify.
YAML – or YAML Ain’t Markup Language, is a relatively new data language that’s growing quickly in popularity in part due to its human-friendliness. The data structure is defined by line separation and indentation, and reduces the dependency on structural characters like parentheses, commas and brackets.
Here's the same person data expressed in YAML.
firstName: John
lastName: Doe
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
This format is more readable than JSON and is often used for configuration files that need to be written by people but parsed by programs. However, YAML is the newest of these data formats and doesn't have as much support in programming languages as JSON and XML.
What is NoSQL / semi-structured data?
Unstructured data
The organization of unstructured data is ambiguous. Unstructured data is often delivered in files, such as photos or videos. The video file itself may have an overall structure and come with semi-structured metadata, but the data that comprises the video itself is unstructured. Therefore, photos, videos, and other similar files are classified as unstructured data.
Examples of unstructured data include:
- Media files, such as photos, videos, and audio files
- Office files, such as Word documents
- Text files
- Log files
Now that you know the differences between each kind of data, let's look at the data sets used in an online retail business, and classify them.
Product catalog data
Product catalog data for an online retail business is fairly structured in nature, as each product has a product SKU, a description, a quantity, a price, size options, color options, a photo, and possibly a video. So, this data appears relational to start with, as it all has the same structure. However, as you introduce new products or different kinds of products, you may want to add different fields as time goes on. For example, new tennis shoes you're carrying are Bluetooth-enabled, to relay sensor data from the shoe to a fitness app on the user’s phone. This appears to be a growing trend, and you want to enable customers to filter on "Bluetooth-enabled" shoes in the future. You don't want to go back and update all your existing shoe data with a Bluetooth-enabled property, you simply want to add it to new shoes.
With the addition of the Bluetooth-enabled property, your shoe data is no longer homogenous, as you've introduced differences in the schema. If this is the only exception you expect to encounter, you can go back and normalize the existing data so that all products included a "Bluetooth-enabled" field to maintain a structured, relational organization. However, if this is just one of many specialty fields that you envision supporting in the future, then the classification of the data is semi-structured. The data is organized by tags, but each product in the catalog can contain unique fields.
Data classification: Semi-structured
Photos and videos
The photos and videos displayed on product pages are unstructured data. Although the media file may contain metadata, the body of the media file is unstructured.
Data classification: Unstructured
Business data
Business analysts want to implement business intelligence to perform inventory pipeline evaluations and sales data reviews. In order to perform these operations, data from multiple months needs to be aggregated together, and then queried. Because of the need to aggregate similar data, this data must be structured, so that one month can be compared against the next.
Data classification: Structured
Summary
Data may be classified in one of three ways: structured, semi-structured, and unstructured. Understanding the differences so that you can classify your own data will help you choose the correct storage solution.
To recap, structured data is organized data that neatly fits into rows and columns in tables. Semi-structured data is still organized and has clear properties and values, but there's variety to the data. Unstructured data doesn't fit neatly into tables, nor does it have a schema.
Determine operational needs
Once you've identified the kind of data you're dealing with (structured, semi-structured, or unstructured), the next step is to determine how you'll use the data. For example, as an online retailer you know customers need quick access to product data, and business users need to run complex analytical queries. As you work through these requirements, taking your data classification into account, you can start to plan your data storage solution.
Here, you'll go through some of the questions to ask when determining what to do with your data.
Operations and latency
What are the main operations you'll be completing on each data type, and what are the performance requirements?
Ask yourself these questions:
- Will you be doing simple lookups using an ID?
- Do you need to query the database for one or more fields?
- How many create, update, and delete operations do you expect?
- Do you need to run complex analytical queries?
- How quickly do these operations need to complete?
Let’s walk through each of the data sets with these questions in mind and discuss the requirements.
Product catalog data
For product catalog data in the online retail scenario, customer needs are the highest priority. Customers will want to query the product catalog to find, for example, all men's shoes, then men's shoes on sale, and then men's shoes on sale in a particular size. Customer needs may require lots of read operations, with the ability to query on certain fields.
In addition, when customers place orders, the application must update product quantities. The update operations need to happen just as quickly as the read operations so that users don't put an item in their shopping carts when that item has just sold out. This will not only result in a large number of read operations, but will also require increased write operations for product catalog data. Be sure to determine the priorities for all the users of the database, not just the primary ones.
Photos and videos
The photos and videos that are displayed on product pages have different requirements. They need fast retrieval times so that they are displayed on the site at the same time as product catalog data, but they don't need to be queried independently. Instead, you can rely on the results of the product query, and include the video ID or URL as a property on the product data. So, photos and videos need only be retrieved by their ID.
In addition, users will not make updates to existing photos or videos. They may, however, add new photos for product reviews. For example, a user might upload an image of themselves showing off their new shoes. As an employee, you also upload and delete product photos from your vendor, but that update doesn't need to happen as fast as your other product data updates.
In summary, photos and videos can be queried by ID to return the whole file, but creates and updates will be less frequent and are less of a priority.
Business data
For business data, all the analysis is happening on historical data. No original data is updated based on the analysis, so business data is read-only. Users don't expect their complex analytics to run instantly, so having some latency in the results is okay. In addition, business data will be stored in multiple data sets, as users will have different access to write to each data set. However, business analysts will be able to read from all databases.
Summary
When deciding what storage solution to use, think about how your data will be used. How often will your data be accessed? Is your data read-only? Does query time matter? The answers to these questions will help you decide on the best storage solution for your data.
Group multiple operations in a transaction
200 XP
Applications may need to group a series of data updates together, because a change to one piece of data needs to result in a change to another piece of data. Transactions enable you to group these updates so that if one event in a series of updates fails, the entire series can be rolled back, or undone.
For example, as an online retailer you might use a transaction for the placement of an order and payment verification. The grouping of the related events ensures that you don't reduce your inventory levels until an approved form of payment is received.
Here, you'll learn about transactions and whether they're required for your data.
What is a transaction?
A transaction is a logical group of database operations that execute together.
Here's the question to ask yourself regarding whether you need to use transactions in your application: Will a change to one piece of data in your dataset impact another? If the answer is yes, then you'll need support for transactions in your database service.
Transactions are often defined by a set of four requirements, referred to as ACID guarantees. ACID stands for Atomicity, Consistency, Isolation, and Durability:
- Atomicity means a transaction must execute exactly once and must be atomic; either all of the work is done, or none of it is. Operations within a transaction usually share a common intent and are interdependent.
- Consistency ensures that the data is consistent both before and after the transaction.
- Isolation ensures that one transaction is not impacted by another transaction.
- Durability means that the changes made due to the transaction are permanently saved in the system. Committed data is saved by the system so that even in the event of a failure and system restart, the data is available in its correct state.
When a database offers ACID guarantees, these principles are applied to any transactions in a consistent manner.
OLTP vs OLAP
Transactional databases are often called OLTP (Online Transaction Processing) systems. OLTP systems commonly support lots of users, have quick response times, and handle large volumes of data. They are also highly available (meaning they have very minimal downtime), and typically handle small or relatively simple transactions.
On the contrary, OLAP (Online Analytical Processing) systems commonly support fewer users, have longer response times, can be less available, and typically handle large and complex transactions.
The terms OLTP and OLAP aren't used as frequently as they used to be, but understanding them makes it easier to categorize the needs of your application.
Now that you're familiar with transactions, OLTP, and OLAP, let's walk through each of the data sets in the online retail scenario, and determine the need for transactions.
Product catalog data
Product catalog data should be stored in a transactional database. When users place an order and the payment is verified, the inventory for the item should be updated. Likewise, if the customer's credit card is declined, the order should be rolled back, and the inventory should not be updated. These relationships all require transactions.
Photos and videos
Photos and videos in a product catalog don't require transactional support. These files are changed only when an update is made or new files are added. Even though there is a relationship between the image and the actual product data, it's not transactional in nature.
Business data
For the business data, because all of the data is historical and unchanging, transactional support is not required. The business analysts working with the data also have unique needs in that they often require working with aggregates in their queries, so that they can work with the totals of other smaller data points.
Summary
Ensuring that your data is in the correct state is not always an easy task. Transactions can help by enforcing data integrity requirements on your data. If your data benefits from ACID principles, then choose a storage solution that supports transactions.
Choose a storage solution on Azure
100 XP
Choosing the correct storage solution can lead to better performance, cost savings, and improved manageability. Here, you'll apply what you've learned about the data in your online retail scenario, and find the best Azure service for each data set.
Product catalog data
Data classification: Semi-structured because of the need to extend or modify the schema for new products
Operations:
- Customers require a high number of read operations, with the ability to query many fields within the database.
- The business requires a high number of write operations to track its constantly changing inventory.
Latency & throughput: High throughput and low latency.
Transactional support: Because all of the data is both historical and yet changing, transactional support is required.
Recommended service: Azure Cosmos DB
Azure Cosmos DB supports semi-structured data, or NoSQL data, by design. So, supporting new fields, such as the "Bluetooth-enabled" field or any new fields you need in the future, is a given with Azure Cosmos DB.
Azure Cosmos DB supports SQL for queries and every property is indexed by default. You can create queries so that your customers can filter on any property in the catalog.
Azure Cosmos DB is also ACID-compliant, so you can be assured that your transactions are completed according to those strict requirements.
As an added plus, Azure Cosmos DB also enables you to replicate your data anywhere in the world with the click of a button. So, if your e-commerce site has users concentrated in the US, France, and England, you can replicate your data to those data centers to reduce latency, as you've physically moved the data closer to your users.
Even with data replicated around the world, you can choose from one of five consistency levels. By choosing the right consistency level, you can determine the tradeoffs to make between consistency, availability, latency, and throughput. You can scale up to handle higher customer demand during peak shopping times, or scale down during slower times to conserve cost.
Why not other Azure services?
Azure SQL Database would be an excellent choice for this data set if you could identify the subset of properties that are common for most of the products and the variable properties that might not exist in some products. Azure SQL Database enables you to combine structured data in the columns, and semi-structured data stored as JSON columns that can be easily extended. Azure SQL Database can provide many of the same benefits of Azure Cosmos DB, but it provides little benefit if the structure of your data is changing in different entities, and you cannot pre-define a set of common properties that are repeated in most of the entities. Unlike Azure CosmosDB that indexes every property in the documents, in Azure SQL Database you need to explicitly define what properties from semi-structured documents should be indexed. Azure Cosmos DB is better choice for highly unstructured and variable data where you cannot predict what are the properties that should be indexed.
Other Azure services, such as Azure Table storage, Azure HBase as a part of HDInsight, and Azure Cache for Redis, can also store NoSQL data. In this scenario, users will want to query on multiple fields, so Azure Cosmos DB is a better fit. Azure Cosmos DB indexes every field by default, whereas the other services are limited in the data they index, and querying on non-indexed fields results in reduced performance.
Photos and videos
Data classification: Unstructured
Operations:
- Only need to be retrieved by ID.
- Customers require a high number of read operations with low latency.
- Creates and updates will be somewhat infrequent and can have higher latency than read operations.
Latency & throughput: Retrievals by ID need to support low latency and high throughput. Creates and updates can have higher latency than read operations.
Transactional support: Not required
Recommended service: Azure Blob storage
Azure Blob storage supports storing files such as photos and videos. It also works with Azure Content Delivery Network (CDN) by caching the most frequently used content and storing it on edge servers. Azure CDN reduces latency in serving up those images to your users.
By using Azure Blob storage, you can also move images from the hot storage tier to the cool or archive storage tier, to reduce costs and focus throughput on the most frequently viewed images and videos.
Why not other Azure services?
You could upload your images to Azure App Service, so that the same server that is running your app is serving up your images. This solution would work if you didn't have many files. But if you have lots of files, and a global audience, you'll get more performance results by using Azure Blob storage with Azure CDN.
Business data
Data classification: Structured
Operations: Read-only, complex analytical queries across multiple databases
Latency & throughput: Some latency in the results is expected based on the complex nature of the queries.
Transactional support: Not required
Recommended service: Azure SQL Database
Business data will most likely be queried by business analysts, who are more likely to know SQL than any other query language. Azure SQL Database could be used as the solution by itself, but pairing it with Azure Analysis Services enables data analysts to create a semantic model over the data in SQL Database. The data analysts can then share it with business users, so that they only need to connect to the model from any business intelligence (BI) tool to immediately explore the data and gain insights.
Why not other Azure services?
Azure Synapse supports OLAP solutions and SQL queries, but your business analysts will need to perform cross-database queries, which Azure Synapse does not support.
Azure Analysis Services could be used in addition to Azure SQL Database, but your business analysts are more well-versed in SQL than in working with Power BI. Therefore, they'd like a database that supports SQL queries, which Azure Analysis Services does not. In addition, the financial data you're storing in your business data set is relational and multidimensional in nature. Azure Analysis Services supports tabular data stored on the service itself, but not multidimensional data. To analyze multidimensional data with Azure Analysis Services, you can use a direct query to the SQL Database.
Azure Stream Analytics is a great way to analyze data and transform it into actionable insights, but its focus is on real-time data that is streaming in. In this scenario, the business analysts are looking at historical data only.
Summary
Each type of data has different storage requirements, and it's your job to figure out which solution is best. Always consider the type of data, the operations required, expected latency, and the need for transactional support.

Comments
Post a Comment